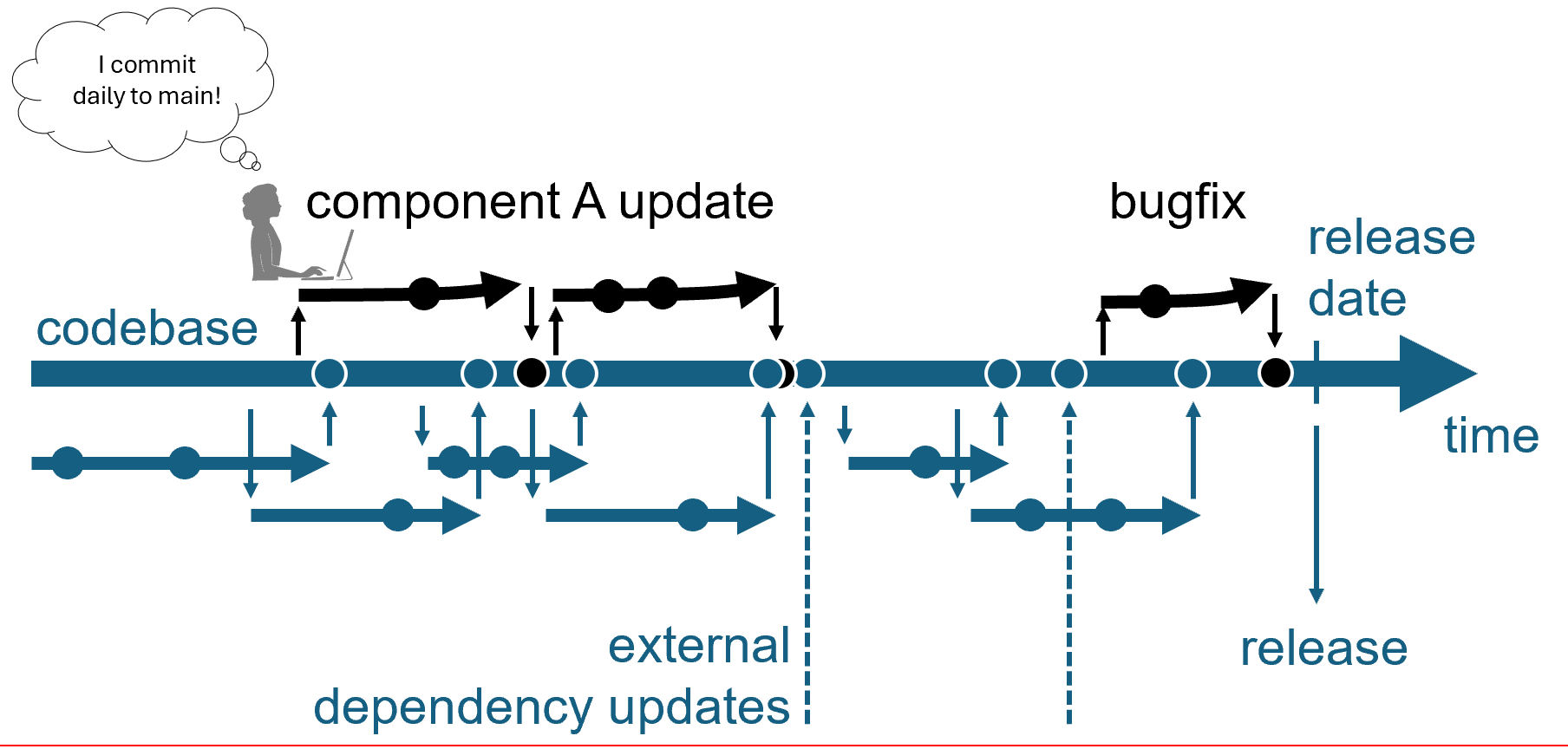
We continuously develop at the head of main.¶
A significant driver of developer frustration and inefficiency is having to support and align multiple versions of units, components, and tools. Versions create an additional dimension of complexity in an environment that is already complex enough.
The de facto standard for versioning is SemVer. SemVer works well on limited scales. However, things get tricky when not thinking about individual dependencies but very large dependency networks at scale over time. See [1] for an excellent summary on this topic.
Given a huge monolithic codebase in a single repository, our straight-forward best-practice solution to conflicting component versions within this repo is to not have versions.
Instead of creating a new version with every change of a component, we merge all changes to the head of main (after being tested well, more on that later). This style of development is called “Trunk Based Development”:
The one version rule¶
Assume we need to change a component. We modify its code, run the tests, and merge the change to the head of main. No need for a version here. There is only one version: “The current one.”
Consequently, at any given point in time, there is only one version for each component on main. This version is tested to work with all the other components on main at this point in time. The same holds for any other point in time in the past, that is, all commits of main. Obviously, this only works if we work in one repository or have any other means to synchronize repositories, such as Git submodules.
Coming back to the present, having only one version of a component reduces maintenance effort:
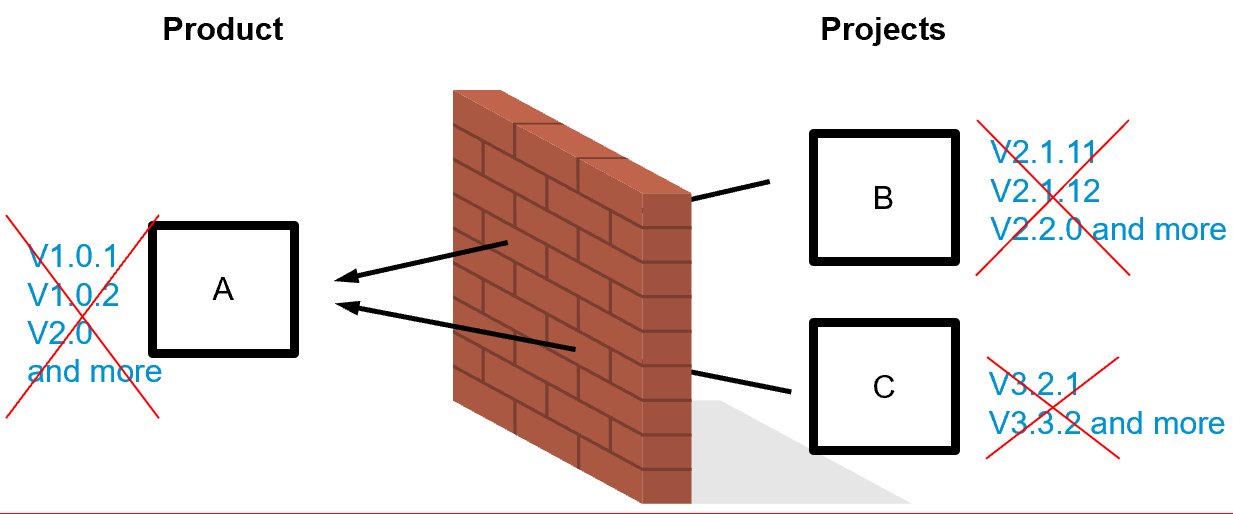
Looking at the example above, ask yourself: “What versions of component A need to be compatible with what versions of component B?” Now imagine you have 6000 components with 5 different versions depending on each other.
If there are no versions, there is no need to make the different versions of A, B, and C compatible. The only thing you need to make sure is that whatever is at the head of main, is compatible. This makes things a lot easier. Of course, there is also a downside. A change in a component needs to be compatible with all the other dependent components already at the time of making the change. This means that when you, for example, change some functionality in component A, you need to fix all the consumers of A in the same pull request, in our example, B and C. Alternatively, you may use patterns such as expand and contract if the change is too large for a single pull request, more on this later. This fixes B and C as before, just over the course of several pull requests.
Even if another team owns component B and C, these components need to be fixed. Changes in A must not be merged if they break B or C. Releasing a new version of A, and leaving the change of B and C for later is not an option. This only delays the change. You will save work now, but for sure not in the long run as the longer you wait, the more cumbersome the change and all related complications will get.
We shift left¶
Notably, this is a paradigm shift in the way we develop software. For you, as a feature owner, this means that you become responsible for integrating, configuring, and activating all new features and required feature changes in all target projects. This might, on the one hand, require multiple model and configuration changes. On the other hand, you are provided with valuable feedback about the actual usage of your feature.
When working in this mode, teams become end-to-end responsible for their feature. This responsibility includes not only integration, configuration, and activation but also providing documentation, unit tests, and platform-level feature verification criteria to project owners so that a feature can be verified in the project context in case the feature is activated. The feature acceptance criteria for the specific projects need to be provided to the respective project owners. Furthermore, teams also become responsible that their feature generates code, compiles, links, and tests fast, more on this later. Being responsible does not mean that you need to do all the work by yourself, but in reality, more work will need to be done by the product, and less by the project.
The total amount of work to be done remains the same. We just do it earlier in the development cycle…
work in progress, to be continued…
We collaborate on main¶
In trunk-based development, development still happens asynchronously on branches before merging to main. The critical distinction to branch-based development is that collaboration between different team members and other teams happens via merging to a main and then pulling from main, and not via committing to the same “private” branch. Thus, only one person or pair is allowed to work on one branch. Once work is finished, the branch is merged to main.
In other words, trunk-based development needs to be continuous. There is a long debate on how often work needs to be merged to main. The evidence is clear: the more often you share, the better, and there is no limit here.
A well-established best practice is to merge to main at least daily. Doing so is not easy, but it can be done by following the practices below leading to superfast feedback cycles and a much less stressful developer life.