Welcome to software engineering.¶
Writing new code is easy. We all learned how to write small programs at the university, at our previous internship, or by ourselves. We all feel confident writing new code. We press run, and no surprise, the new code works on our machine. Therefore, we think we need to follow no procedures when coding.
Being a part of a large company, the next step is to integrate our new code. Integrating means “putting” our code into the millions of lines of working code already existing in the company’s codebase. To make things even more complicated, our more than 300 colleagues also integrate their new code simultaneously. The sheer countless external libraries we use, including their dependencies and the dependencies of their dependencies, are also constantly updated. This creates a moving integration target.
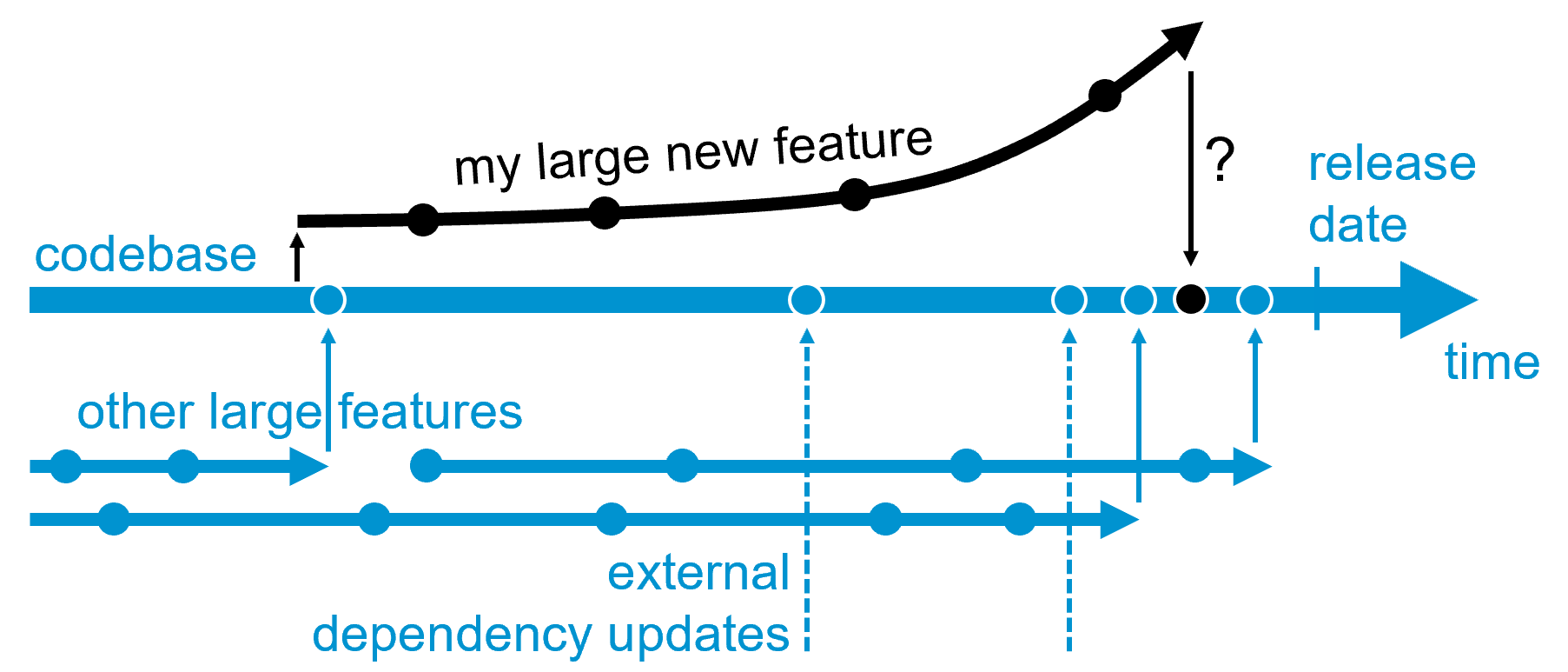
Integration is hard. Thus, we tend to avoid it. As a result, the code-changes we work on get bigger and bigger. Meanwhile, the codebase has diverged even more from where it was when we started the new feature. The longer we wait, the exponentially worse things get, especially just before a release when we are already in a hurry, as all the others are.
Still, we can do it. We work extra-long shifts. We find shortcuts such as skipping testing or writing no documentation. To speed up quality checks, we trick the system. There is always a loophole left open that we can exploit. This all does not feel right. Short-term thinking cannot be good for our company in the long term, can it? We feel incredibly uncomfortable, but managers told us we need to deliver to stay in business. Lately, this happens so often that we browse other companies’ job offers while waiting for our endless builds to finish. Fortunately, there are so many cool things about our company that we power through.
So far, so good, but wait! The next day, we receive a call that the piece of code we had carefully designed broke something else at some place far away in the codebase. Really? How could we anticipate that code-conflict in a codebase of 30+ million lines? We have just heard of this part of the codebase for the first time.
We surrender to our fate. We start the debugger: bug-fixing time! If only we could reproduce the bug locally…
Your life does not need to be painful!¶
We are not the first ones to fail. Programmers before us have made the same mistakes again and again. We who love to code underestimate the unforgiving power of exponentially growing complexity. If not managed well, this complexity can quickly outgrow the brain capacity of the smartest among us, given scale and time. No need to be embarrassed; we are all human.
There is a profound difference between coding and software engineering. As Titus Winters, former C++ libraries lead of Google, once said: “Software engineering is programming integrated over time and scale.”
Sure, we all want to master time and scale. We all want to do a great job, but how?
There is no one-fits-all recipe for software engineering. The best-practice target picture for open-source projects with sporadic contributors (the kind of environment you might be most familiar with) is different from the target picture of large enterprise setups with hundreds of full-time employees. Still, we do not need to be like Netflix with its microservices or Google with its gigantic mono repo and custom tooling.
We are more than 300 full-time developers. We trust each other. This setup differs from open-source development where long-time branching is inevitable and developers need to review code from untrusted, potentially malicious contributors.
Our 30+ million lines codebase is monolithic and full of legacy. Large-scale refactoring across libraries is common. We see this daily when pull requests span several, if not dozens, of repositories.
There is also no end date for our codebase. We will need to support all our customer projects with new features for many more years. Except for ‘’L4-Releases’’ (the ones with lots of cars on the road), our customers will not pay us for keeping any branch up to date.
Our code must adhere to regulatory standards such as ISO 26262 and ASPICE to minimize the risk of failure. This requires very formal requirements documentation and tracing from system design to testing throughout the so-called “V-Model”.
In our business, developers change teams occasionally and stay only for several years. Thus, we need a development scheme that is quickly learned, easily understood, and straightforwardly enforced. In engineering, simplicity cannot be underestimated.
We should also not employ more than one development schema for personal preferences, customer preferences, or simply because a certain way of working looks easier for one particular use case. What looks promising in the short run, often turns out to not scale well in the long run, especially when people need to switch teams or interact with other teams.
That being said, there is a well-established industry best practice for our particular setup that has proven to scale and stand the test of time more efficiently than developing large features in isolation on branches: Continuous development at the head of a single repository.
How we want to achieve this (new) way of working will be explained in Chapters 2 to Chapter 16:
In short, we version control all our product and project code (our “colonies”) in folders within one repository. This repository has a special branch called “main”. Newly developed code is always merged with the head of main starting with a fresh check-out from main. Consequently, we agree as a team to never break main. We achieve this by building, that is, checking our code before merging. In the unlikely case we missed something and cannot correct our mistake fast, we revert to the last known working state to unblock us and our colleagues.
Obviously, this only works if we have a vast number of high-quality tests. Such tests cannot be created after coding has been done. They need to be created iteratively while coding, either test first or code first, then test, then code, and so on in small two-minute cycles. Once we have a battery of good tests that we can rely on to keep main in a releasable state, we release on demand from main to the customer.
Fast feedback is key. This is why we make changes in small increments and immediately merge them to main to see how they integrate with the other code. Collaboration with team members also happens on main and not on feature branches. Frequently merging to main becomes a pain when a build (including all tests and static code analysis) takes hours to complete. Thus, we go to great lengths to achieve a 10-minute build, which in turn allows us to merge “something” at least daily. No matter how complicated the code, there is always a function or refactoring worth sharing at the end of the day.
A 10-minute build sounds too good to be true, but can be achieved using a build-system that never builds any part of the software twice but instead uses the cached result from a prior execution. Such caching can only work well if all build-steps are deterministic (same input - same output) and hermetic (all inputs controlled). Furthermore, the codebase needs to be decoupled into small build-steps with all dependencies being known beforehand. Thus, as always, to win, we need to educate ourselves and invest in architecture.
Our life does not need to be painful! Developing new features and even bug-fixing can be an enjoyable experience in the setup outlined above. The critical game changer is a fast build that reports back test results within ten minutes. When using a sophisticated build system, there is no difference anymore if we start the build locally or from the CI in a pull request: speed and result are the same.
Why ten minutes? Ten minutes is enough time to drink morning coffee and think about the next task instead of all dependencies in a 30+ million lines codebase. If you do not drink coffee, feel free to do some stretches. By the way, the worst you can do is to switch tasks, as this takes approx. Fifteen minutes are only in one direction, so half an hour of unproductivity will be gone before you may continue working on the code.
It’s all about the mindset.¶
Unfortunately, introducing continuous development at the head of a single repository cannot be achieved by setting up some fancy build system from Google and introducing mandatory, automatically checked rules right before integration.
Firstly, developers are smart. That is why we hired them in the first place. They will succeed if they have to trick the system for whatever good or bad reason. Let us take code coverage as an example. There is a subtle difference between developers expecting a high level of coverage and managers requiring a high level of coverage. The latter is easily reachable with low-quality tests, or taken to the extreme, generating tests.
Secondly, programming is and will always be a tradeoff. Enforcing a clean-code rule such as “a function must not have more than three parameters and none of them should be boolean” will bring us nowhere. Still, there is more truth to this idea than we might think. The same holds for how often we should integrate our code. Should we integrate daily? Or should we integrate every two days as the build takes forever? Or should we integrate now as we just completed a large refactoring? The answer will in most cases be: “It depends”
Thirdly, we cannot cover any possible situation we will encounter in our daily business with a rule. What to do then?
We believe that mindset is more important than strict rules. Remember the assumption from above: We trust each other. This is why we will focus on mindset in the sections that follow and hope that these guiding principles will help you to make the best possible choices in whatever situation we are in.
Changing habits is hard. Changing habits takes a long time. Give it a try. Trust me, it’s worth it!